2019年无论是C语言榜单却是在网络金融行业,Python始终倍受争论,究竟是Java炙手可热却是Python炙手可热也是始终让人争执的话题。
随着网络时代的插值更新,人工智慧的兴起,PythonC语言也随之被人们广泛学习,Python统计数据挖掘、Python web全栈、Python智能化网络管理等等都很畅销,其中还包括了Python食腐。但很对人觉得Python食腐是违规的犯罪行为,也在怀疑他们究竟要不要学食腐,之前有一则该文特别火,就是 》 ,该文里写了因为一名技工因banlist统计数据被抓,所以食腐真的违规吗?今天我们来探索一下。
目前网络世界针对食腐这一块已经透过自身的协定创建起一定的社会规范(Robots协定),但法律条文部分还在创建和完善中。所以Robots协定是什么呢?
1
Robots协定
Robots协定(食腐协定)的全名是“网络食腐排除标准”(Robots Exclusion Protocol),中文网站透过Robots协定告诉搜寻发动机什么样网页能截取,什么样网页无法截取。该协定是国际网络界车辆通行的社会规范,虽然没有载入法律条文,但每两个食腐都如果严格遵守这项协定。
下面以淘宝网的robots.txt为例展开介绍。
User-agent: Baiduspider #腾讯食腐发动机Allow: /article #容许出访/article.htm、/article/12345.comAllow: /oshtmlAllow: /ershouDisallow: /product/ #明令禁止出访/product/12345.comDisallow: / #明令禁止出访除Allow明确规定网页外的其它大部份网页
User-Agent: Googlebot #Google食腐发动机Allow: /articleAllow: /oshtmlAllow: /product #容许出访/product.htm、/product/12345.comAllow: /spuAllow: /dianpuAllow: /wenzhangAllow: /overseaDisallow: /
在上面的robots文档中,淘宝网对用户代理为腾讯食腐发动机展开了明确规定。
以Allow项的值结尾的URL是容许robot出访的。比如,Allow:/article容许腾讯食腐发动机出访/article.htm、/article/12345.com等。
以Disallow项为结尾的镜像是不容许腾讯食腐发动机出访的。比如,Disallow:/product/不容许腾讯食腐发动机出访/product/12345.com等。
最后一行,Disallow:/明令禁止腾讯食腐出访除Allow明确规定网页外的其它大部份网页。
因而,当你在腾讯搜寻“淘宝”的这时候,搜寻结果上方的嘉犁会出现:“由于该中文网站的robots.txt文档存在管制命令(管制搜寻发动机截取),系统无法提供该网页的内容描述”,总的来看。腾讯作为两个搜寻发动机,良好地严格遵守了淘宝网的robot.txt协定,所以你是无法从腾讯上搜寻到淘宝内部的商品信息的。

淘宝的Robots协定对Google食腐的福利待遇则不一样,和腾讯食腐不同的是,它容许Google食腐banlist商品的网页Allow:/product。因而,当你在Google搜寻“淘宝iphone7”的这时候,能搜寻到淘宝中的商品,总的来看。
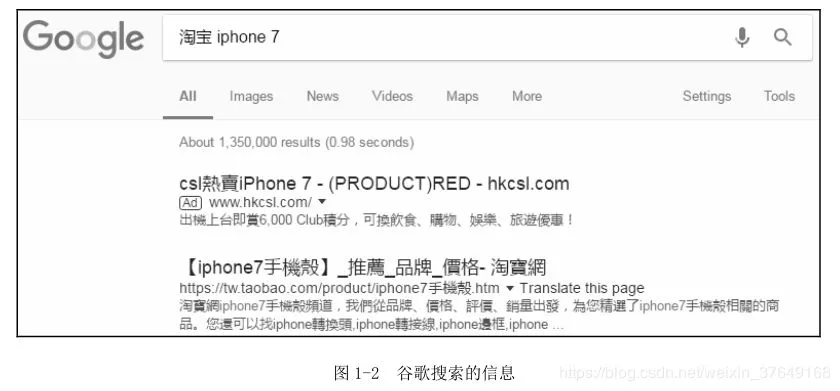
当你banlist中文网站统计数据时,无论是否只供个人采用,都如果严格遵守Robots协定。
加入VIP团体会员,上千本图书、上七处专业课程等你免费学

2
网络食腐的束缚
除上述Robots协定之外,我们采用网络食腐的这时候还要对他们展开束缚:过于快速或者频繁的网络食腐单厢对伺服器产生巨大的压力,中文网站可能封堵你的IP,甚至采取进一步的法律条文行动。因而,你须要束缚他们的网络食腐犯罪行为,将请求的速度限量发行在两个合理的范围之内。
banlist中文网站的这时候须要管制他们的食腐,严格遵守Robots协定和束缚网络食腐程序的速度;在采用统计数据的这时候必须严格遵守中文网站的知识产权。
所以只要你合理利用就不会违规,食腐却是能学的哦,毕竟食腐对统计数据挖掘真的非常有用,所以食腐该怎么学呢?今天来教大家撰写两个简单的食腐!
3
撰写第两个简单的食腐
第一步:
获取网页
#!/usr/bin/python# coding: utf-8
import requests #引入包requestslink = "http://www.santostang.com/" #定义link为目标网页地址# 定义请求头的浏览器代理,伪装成浏览器headers = {User-Agent : Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6}
r = requests.get(link, headers= headers) #请求网页print (r.text) #r.text是获取的网页内容代码
上述代码就能获取博客首页的HTML代码,HTML是用来描述网页的一种语言,也就是说网页呈现的内容背后都是HTML代码。如果你对HTML不熟悉的话,能先去w3school(http://www.w3school.com.cn/html/index.asp)学习一下,大概花上几个小时就能了解HTML。
在上述代码中,首先import requests引入包requests,之后获取网页。
(1)首先定义link为目标网页地址。
(2)之后用headers来定义请求头的浏览器代理,展开伪装
(3)r是requests的Response回复对象,我们从中能获取想要的信息。r.text是获取的网页内容代码。
运行上述代码得到的结果总的来看。

第二步:
提取须要的统计数据
#!/usr/bin/python# coding: utf-8
import requestsfrom bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSoup
link = "http://www.santostang.com/"headers = {User-Agent : Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6}r = requests.get(link, headers= headers)
soup = BeautifulSoup(r.text, "html.parser") #采用BeautifulSoup解析
#找到第一则该文标题,定位到class是"post-title"的h1元素,提取a,提取a里面的字符串,strip()去除左右空格title = soup.find("h1", class_="post-title").a.text.strip()print (title)
在获取整个网页的HTML代码后,我们须要从整个网页中提取第一则该文的标题。
这里用到BeautifulSoup这个库对网页展开解析,BeautifulSoup将会在第4章展开详细讲解。首先须要导入这个库,然后把HTML代码转化为soup对象,接下来用soup.find(“h1”,class_=“post-title”).a.text.strip()得到第一则该文的标题,并且打印出来
soup.find(“h1”,class_=“post-title”).a.text.strip()的意思是,找到第一则该文标题,定位到class是"post-title"的h1元素,提取a元素,提取a元素里面的字符串,strip()去除左右空格。
对初学者来说,采用BeautifulSoup从网页中提取须要的统计数据更加简单易用。
所以,我们怎么从所以长的代码中准确找到标题的位置呢?
这里就要隆重介绍Chrome浏览器的“检查(审查元素)”功能了。下面介绍找到须要元素的步骤。
步骤01
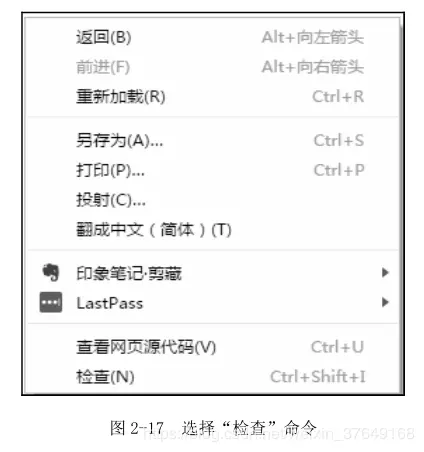
采用Chrome浏览器打开博客首页www.santostang.com。右击网页网页,在弹出的快捷菜单中单击“检查”命令,总的来看。
步骤02
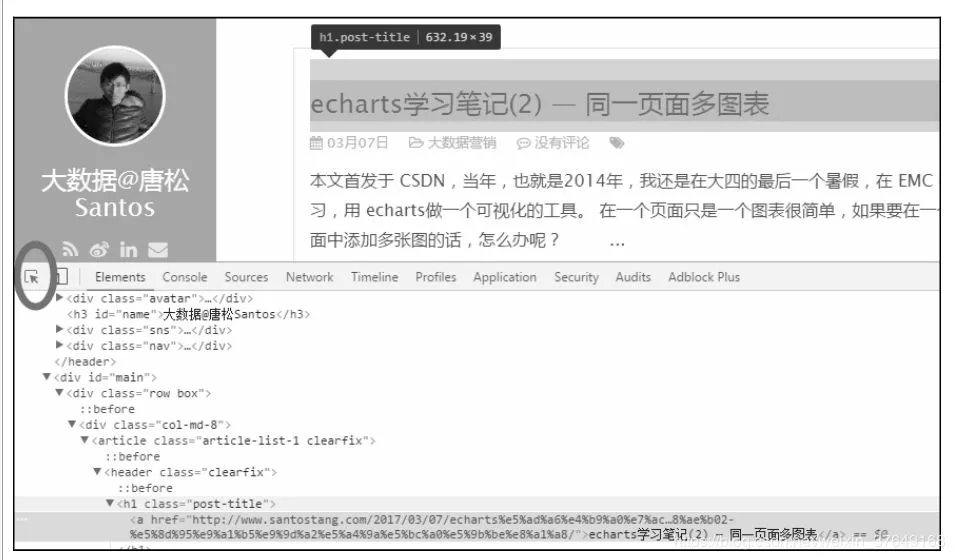
出现如下图所示的审查元素网页。单击左上角的鼠标键按钮,然后在网页上单击想要的统计数据,下面的Elements会出现相应的code所在的地方,就定位到想要的元素了。
步骤03
在代码中找到标蓝色的地方,为echarts学习笔记(2)–同一网页多图表。我们能用soup.find("h1",class_="post-title").a.text.strip()提取该博文的标题。
第三步:存储统计数据
import requestsfrom bs4 import BeautifulSoup #从bs4这个库中导入BeautifulSoup
link = "http://www.santostang.com/"headers = {User-Agent : Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6}r = requests.get(link, headers= headers)
soup = BeautifulSoup(r.text, "html.parser") #采用BeautifulSoup解析title = soup.find("h1", class_="post-title").a.text.strip()print (title)
# 打开两个空白的txt,然后采用f.write载入刚刚的字符串titlewith open(title_test.txt, "a+") as f:f.write(title)
存储到本地的txt文档非常简单,在第二步的基础上加上2行代码就能把这个字符串保存在text中,并存储到本地。txt文档地址如果和你的Python文档放在同两个文档夹。
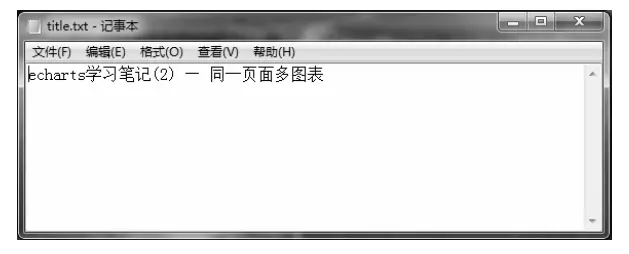
返回文档夹,打开title.txt文档,其中的内容总的来看。
以上就是撰写第两个食腐的方法,你们学会了吗?暂时没学会也没关系,你能慢慢学哦~以上内容自《Python网络食腐从入门到实践(第2版)》
请立即点击咨询我们或拨打咨询热线: ,我们会详细为你一一解答你心中的疑难。项目经理在线
 客服1
客服1